In an age where data drives decisions, the need for accurate, efficient text extraction from images, documents, and handwritten notes has never been greater. Traditional OCR or Optical Character Recognition technology has long been the cornerstone of digitizing printed text. This traditional approach worked by scanning an image or document and analyzing patterns to identify characters. It typically uses image processing to detect edges, shapes, and structures, then matches these patterns against known character templates to convert visual text into digital format.
The major hurdle developers face is that the entire process is rule-based or simply put, it lacks understanding of context, making it prone to errors. The conventional markdown outputs are often a useless plump of characters where we realise all the efforts we had spend was somewhat futile. So in a nutshell, its limitations with context, structure, and error correction has been hindering its effectiveness.
Changing landscape
But with the advent of LLMs and particularly those that can intake images, we are seeing some new possibilities in this realm. In this article, we’ll explore how LLM-based OCR is revolutionizing the field and opening doors to applications that were once beyond reach.
Why does LLM-OCR have an upper hand?
Before exploring a notebook where we will pass a pdf to gpt for advancing LLM based OCR let us see some advantages of this approach and why we identify it to be an evolving game changer.
Contextual Understanding: One of the key advantages of LLM-based OCR over traditional OCR is its ability to understand the context and meaning of text. Traditional OCR approaches focus solely on converting visual text into digital characters, without any comprehension of the text’s semantic content, thus the extracted text may or may not render some meaningful output. In contrast, large language models (LLMs) can interpret context, allowing them to discern meaning and even correct errors based on surrounding information. This functionality is similar to how we humans read, where understanding context helps clarify unclear or ambiguous text.
Self correction: Traditional OCR systems often struggle with poor image quality, unusual fonts, skewed or rotated text, and background noise. These factors can cause errors in the text output, especially when visual clarity is compromised. LLMs, however, can use their language comprehension abilities to make educated guesses about characters or words that may appear unclear. This can be a help like no other with sensitive areas like legal documents. In layman terms they can correct typographical mistakes and handle unusual fonts more effectively by interpreting what “makes sense” within the context.
Improved Formatting: Traditional OCR processes typically output raw, unstructured text, leaving users to manually add structure, layout, and formatting. LLMs can recognize and retain document layouts, identify headers, and handle complex elements like tables and lists. For example say you are evaluating a form where item address is written. It might be spaced anywhere near the word marker “address” and may involve more than one line. Traditional OCR cannot interpret this multi line or spatially disoriented text which an LLM can understand based on its contextual understanding.
Handwriting Recognition and language handling: While traditional OCR often falters with handwriting due to the variability in styles and character shapes, LLMs handle this task more effectively by leveraging their understanding of common writing patterns. They use context to decode unclear words, even when handwriting quality varies, and adapt to different writing styles. This capability makes LLM-based OCR a more powerful tool for digitizing handwritten documents or notes. Also traditional OCR requires separate models for each language, making it challenging to process multilingual documents. LLMs, however, can handle multiple languages simultaneously, interpret mixed-language documents, and even perform translation tasks during OCR.
Post-Processing: Traditional OCR systems often need multiple post-processing steps to clean up the text output, fix formatting issues, and extract key information. This would again require the developers to cling on to various NLP techniques. On the other hand LLMs streamline this process by automatically cleaning up formatting inconsistencies, fixing spacing issues, and standardizing text output. They can also extract relevant information directly, eliminating the need for additional manual post-processing.
Practical Implementation
Now having said all this let us explore this capability with a simple program. What we will be doing is that we will be loading a pdf, saving it as jpeg images and passing these images to an LLM to derive answers to our questions. For your convenience we will be using Google Colab for all these operations.
To start with we will be uploading a four page pdf file on python programming. From the very pdf you can understand the spatial makeup of the document is very much incomprehensible to traditional OCR methodology. Please find the colab notebook here.
A. Initially import the necessary libraries

Installing the openai library enables us to make API calls to Openai from where we will be using LLM models and GPT-4o is the one we will be using here. Poppler-utils is a suite of command-line tools for working with PDF files. One of its popular tools, pdftotext, converts PDF files to plain text, which is useful for extracting text from PDFs. Poppler is often a dependency for libraries that process PDFs in Python, especially when you need to convert PDF pages into images or text. Pdf2image is a Python library, which is used to convert PDF pages into images. It relies on Poppler to process PDF files.
B. Now we load our pdf Python_Programs pdf into the contents folder of Colab
C. Convert the pdf into images
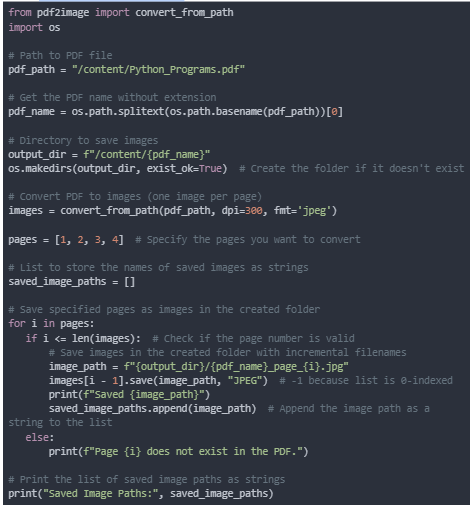
Here we first extract the PDF’s name and create a folder in the specified directory (/content/Python_Programs). After converting the PDF into images (one per page), it saves the specified pages (e.g., pages 1, 2, 3, and 4) as .jpg files within the newly created folder. Each image is saved with a filename indicating the original PDF name and page number (e.g., Python_Programs_page_1.jpg). This approach provides a structured output, organizing each page’s image into a single folder with descriptive filenames, making it easy to identify and retrieve individual page images. Thus our output in the folder structure would look like this.
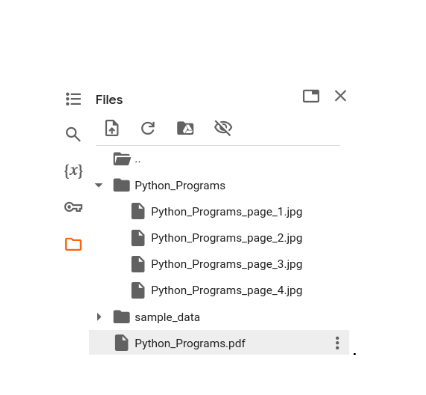
D. Processing the images
This is achieved with the help of three functions.
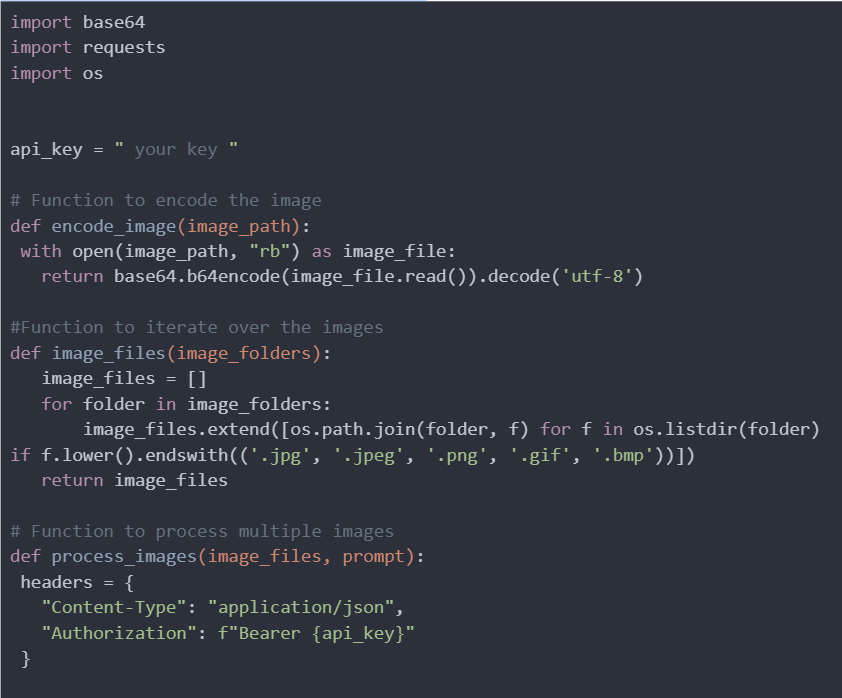
First, the encode_image function reads an image file in binary mode, encodes it in base64, and returns the encoded string, which is essential for embedding images directly in JSON requests. Next, the image_files function takes a list of folder paths, iterates through each folder, and collects all image file paths with specific extensions (.jpg, .jpeg, .png, .gif, and .bmp), returning a flat list of these paths.
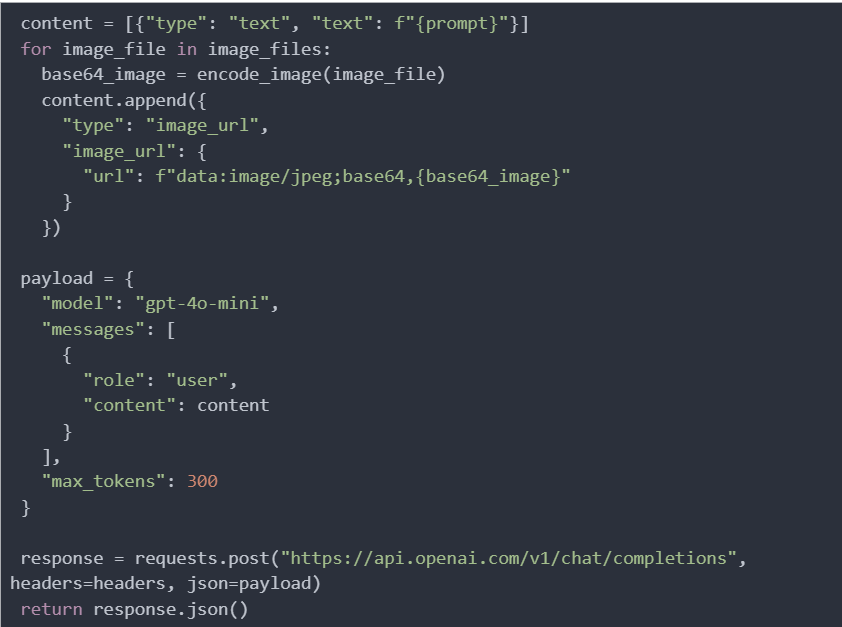
Finally, the process_images function accepts the list of image file paths and a text prompt, sets the request headers, initializes the message content with the prompt, adds each image as a base64-encoded string, and constructs a payload dictionary that specifies the model to be used, the user role, and the assembled message content for sending to the OpenAI API.
E. Then we invoke these functions as

Please note that the folder path is passed as a list. Thus if required you may add more than one folder of images into the payload.
F. Final Output

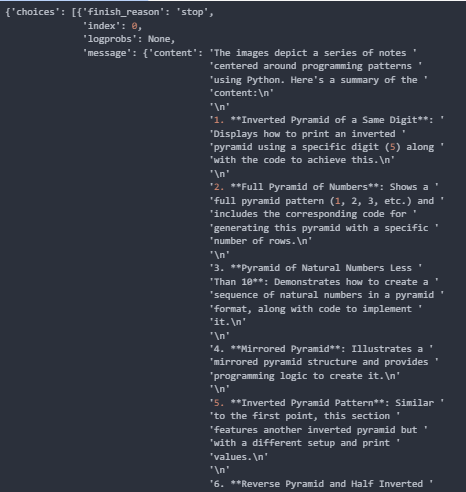
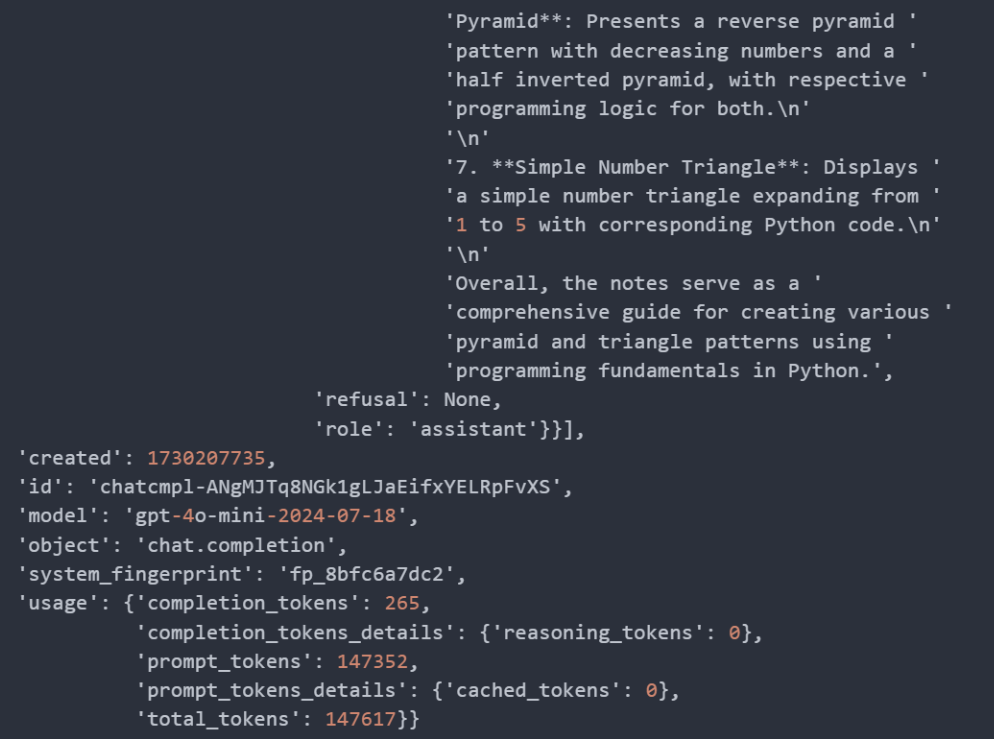
And the result would look like
Way ahead
Hatsoff on your hands on endeavor with LLM based OCR. Please feel free to modify the code to suit your requirements. If you are further interested in similar tech “https://github.com/getomni-ai/zerox” will be a great place to drop by and see some more details.