
Building and integrating RAG pipelines to chatbots can be a great value addition. RAG pipelines combined with chatbots will be able to provide contextually aware responses based on the corpus of knowledge we can add. However after having built quite a number of integrations we have understood that evaluation of the performance and further fine-tuning for improvement is highly crucial.
Such evaluations leverage and ensure the ability to retrieve relevant documents, generate connected answers and serve the customer needs. One tool we use for such evaluation is called Trulens.
This blog will enable you to drive upwards from the very basic understanding of what is an LLM, to RAG, setting up RAG, and how to evaluate a RAG pipeline.
LLMs and shortcomings
Large Language Models (LLMs) are advanced artificial intelligence systems designed to process and generate human-like text. These models are trained on vast amounts of textual data, allowing them to understand and produce coherent language across a wide range of topics and tasks. LLMs use deep learning techniques, usually based on transformer architectures, to capture complex patterns and relationships in language.
They can perform various natural language processing tasks such as text generation, translation, summarization, and question-answering. Popular examples of LLMs include GPT (Generative Pre-trained Transformer) models, BERT (Bidirectional Encoder Representations from Transformers), and their variants. These models find applications in numerous domains, from chatbots and virtual assistants to content creation and data analysis.
RAG
However the major setback arises when the question or query corresponds to what is not present in the training data of an LLM. This can throw up hallucinated or incorrect answers and confuse the user. Here comes the relevance of the RAG or Retrieval Augmented Generation approach as this innovative approach in natural language processing combines two primary components: a retrieval mechanism and a generative model. The retrieval component searches a large database of documents to find relevant information, which the generative model then uses to produce a coherent and contextually appropriate response.
How RAG works
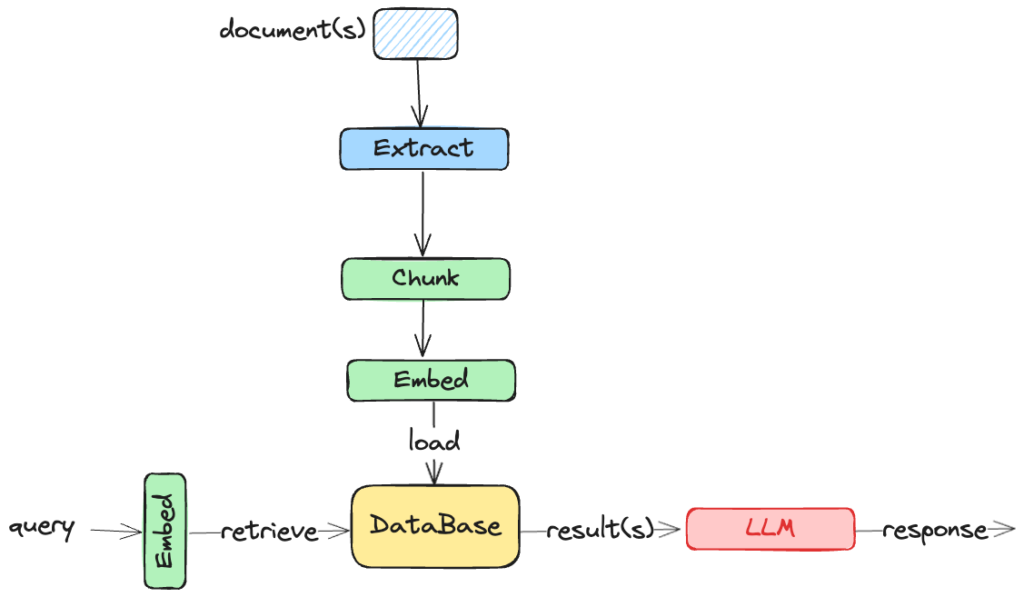
Source: www.deeplearning.ai/resources/generative-ai-courses-guide
RAG pipelines basically involve a few steps. Initially, the document or the knowledge corpus is chunked, vectorised, and stored, and it can be stored in a vector store. Later, when the user generates a query, the query is vectorised and taken for a similarity search in the vector store. Similar vector chunks from the store are retrieved and then passed to LLM with the query so that a befitting answer can be generated.
Some features of RAG give it a great advantage over the concept of fine tuning which is a similar information updation and customisation technology associated with LLM. Unlike fine tuning we do not require a large computationally intensive procedure and updation of the weights of an LLM. Moreover hallucinations or guessed up answers are further reduced compared to fine Tuned models as RAG depends upon retrieving relevant information from a vector base.
Overall RAG can help our chatbots or applications with
- Accurate information
- Up-to-date content
- Relevance to specific needs
Building a functional RAG system
To understand how Retrieval Augmented Generation works, we will build a pipeline using LlamaIndex. Llamaindex is a leading data framework for building LLM applications. In our requirement it helps us to bring together LLM capabilities and Retrieval to work on the pipeline we are setting. All the following are executed in Google Colab for easy and painless trials and following these steps should put your pipeline into work.
Start with the setup
Once you connect your colab instance the first step you would need to do is install the packages using pip.

Opeanai is being used to generate the outputs and function as the LLM provider whereas Trulens will be used to evaluate the outputs of our RAG system which we will be seeing later.
After this set up the open-ai API key which you will obtain at openai website.

Now with the basic setups in place, we will build our RAG pipeline. To begin with, we need a knowledge corpus or in simple terms a document to retrieve information from. For this purpose we will choose a book called “How-to-Build-a-Career-in-AI.pdf” written by Andrew Ng the stalwart in AI and machine learning.
Prepare the data
You can paste the following code and download the book into your Content folder of colab instance

Now we need to load the data from the downloaded pdf. This can be done using the SimpleDirectoryReader of LlamaIndex and the data is stored as a list.

If you check the length of this document it will show a number that is equal to the number of pages so now we will unify it. If you need, you may also chunk it for better context management.

Initialize the LLM, embedding model and vector index
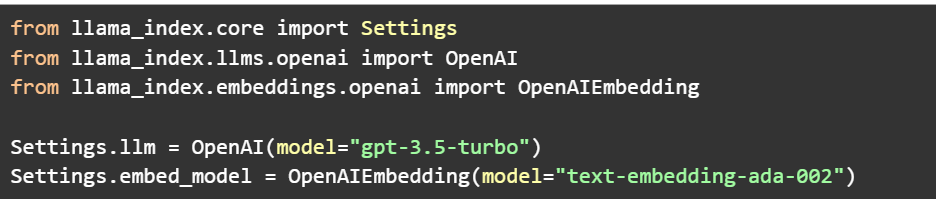
Then we initiate the preferred LLM model and the embedding model.
Now we convert the loaded data in document variable into a vector index.

Set up the Query Engine
With our index created we are all good to set up our first query engine and ask questions to the index we have created.

After this we send our first query.

Upon executing the above code the system retrieves the relevant information chunks and passes it to the LLM with the query. LLM then generates an answer to the question based on the vectors and outputs it through the response variable.
Congratulations, your milestone in implementing a RAG pipeline is achieved. Give yourselves some time to ask other questions and see how your query engine answers all those questions based on the context you have provided i.e, the pdf we have loaded.






