
Now, with our RAG pipeline in place, let us explore the performance of the system. But before that, what do we mean by “performance of a RAG system”? The performance of an RAG system implies how well the system fetches correct responses from the documents previously stored.
Evaluation acts as a quality control mechanism, enabling continuous improvement and maintaining the reliability and effectiveness of RAG systems. Trulens is such a tool that helps us evaluate the performance of an RAG system by evaluating the quality of responses and other dimensions.
The RAG Triad
Trulens provides a concept called RAG Triad- a combination of three evaluations to check our RAG system.

Context Relevance
When a user asks a question, the system needs to fetch information that is directly related to the question. This is crucial because irrelevant information can lead to incorrect or misleading answers.
Thus, Context Relevance ensures that the retrieved context is relevant and helps the language model (LLM) generate accurate and on-point answers.
Groundedness
After retrieving the context, the LLM generates an answer. However, LLMs can sometimes add incorrect details or exaggerate. To avoid this, each part of the response should be checked against the retrieved context to ensure it is factually correct.
This step ensures that the response stays true to the facts and doesn’t include false or misleading information.
Answer Relevance
The final response should directly address the user’s question. This means checking how well the generated answer matches the user’s input.
We can thus ensure that the response is relevant to the question and helps in providing accurate and useful information to the user.
TruLens has adopted the ‘honest, harmless, helpful’ criteria from Anthropic as guidelines for evaluating language model (LLM) applications. These criteria encompass the key qualities that we generally seek in an AI system, including LLM apps. The RAG triad mainly falls in the Honest criteria, and you can check other criteria and read a bit more in the Trulens documentation.
Feedback Functions
Feedback functions are those functions that provide us with a programmatic method for evaluations. In essence, these are the functions that help us evaluate the context relevance, groundedness, and answer relevance. Still, there exists one question; we understand we get some answers from the RAG, and we need to check them under certain criteria.
But what is the metric we match them or with what do we compare these answers? Trulens provides a range of benchmarks, and two such benchmarks are “LLM Evals” and “Ground Truth Evals”. In “LLM evals”, the responses or retrieved-context is checked against answers generated by an LLM for the same query. Thus, we check how good our retrieved answers are against what an LLM already knows.
However, if the document is some information the LLMs were never exposed to, we go for “Ground Truth Evals”. In this method, we make a question-answer set called the “Golden dataset”. Then, we ask the same question to the RAG system. Ground truth evaluation works by comparing the similarity of an RAG response compared to its matching verified response.
Initializing the feedback functions – LLM Evaluation
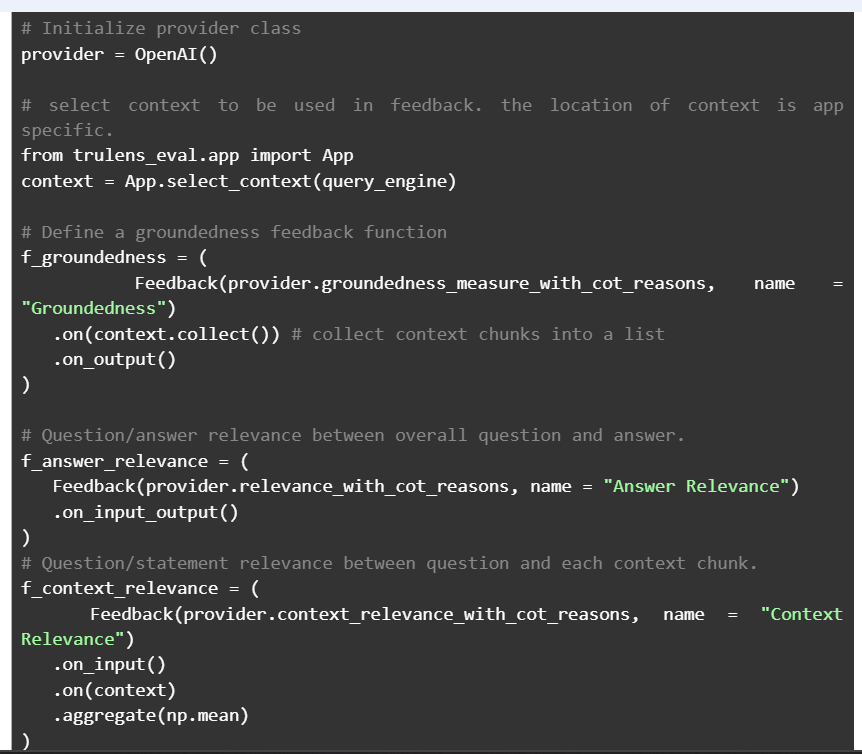
This is an example of LLM eval and here the provider variable actually shows we are using OpenAI generated answers for comparing ourRAG generated answers
We need to set up instrumentation in our application to capture and log the interactions between our RAG system and TruLens. This requires integrating TruLens into our LlamaIndex configuration, allowing us to log queries and capture feedback.
Firstly we initialise a Trullama recorder instance and the app_id is the name of our RAG system.


Then the recorder we started in the previous snippet is used to log queries as context manager. Thus we make sure each query and responses are being duly recorded.

Feedback Analysis
Having done the above steps the next step is to analyze the feedback generated by the application’s responses. This involves retrieving the feedback records, understanding the metrics used, and using the insights to improve our system’s performance. Once the system has been run, we will need to access and display the logged feedback in a meaningful way to ensure effective evaluation and continuous enhancement of our RAG system.
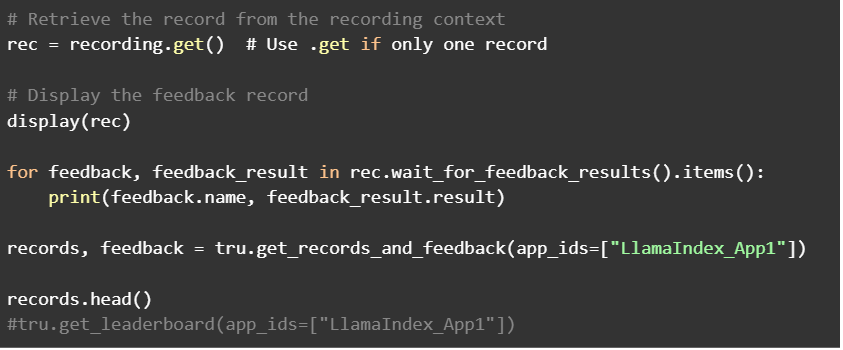
Running the above code gives an output like this.

Higher the values and closer to one, better is the performance. To get a better interactive dashboard view we may run the below code and click the link from Colab.

Initializing the feedback functions – Ground Truth Evaluation
Now let us explore how to initiate evaluation based on Ground Truths based on a Golden Dataset of prepared question and answers. For this we may prepare a csv file with questions in the first column and corresponding answers in the second. There after using pandas we read this into the query chain.

So now our feedback function definition will look like this:
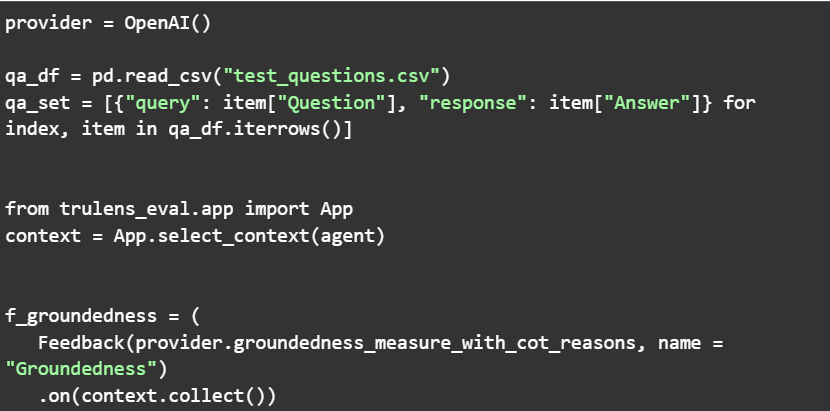
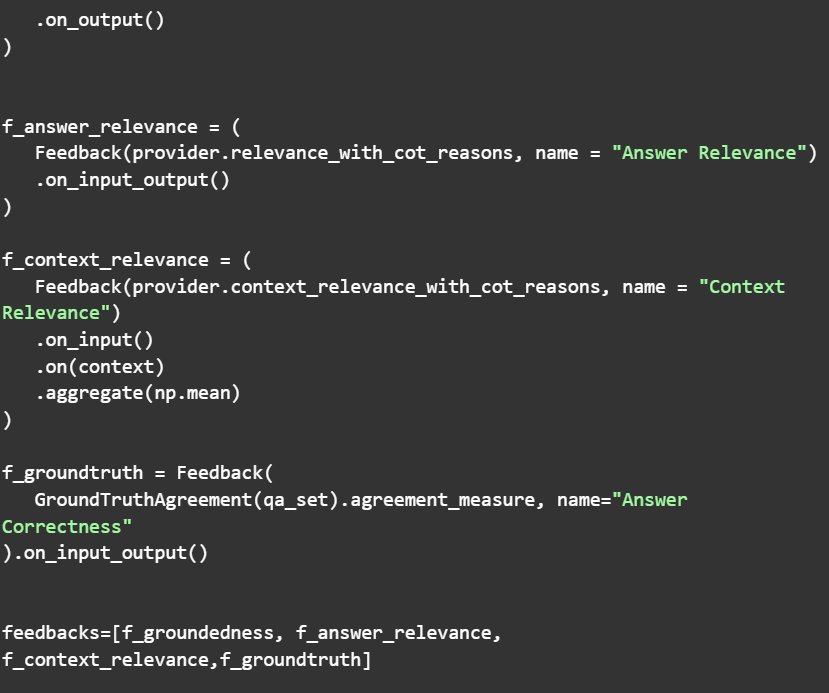
Where, f_groundtruth evaluates the generated answers to the golden dataset. In this case, the recorder is slightly modified as

to iterate through the questions in the prepared csv. All other steps remain the same like “LLM Eval”
Conclusion
We have seen how to build a RAG pipeline and create an evaluation system on top of that. To improve the metrics and fine-tune the RAG system, begin by identifying weak areas through metrics, such as low groundedness scores, and adjust retrieval mechanisms to fetch more relevant documents.
Adopt an iterative development process, making small changes based on feedback and continuously evaluating the system. Improve retrieval strategies by refining search algorithms, expanding the document corpus, and filtering out irrelevant content.
Additionally, fine-tune the generative model by adjusting parameters or training with more data. Regularly analyzing feedback will guide us in optimizing the RAG system’s performance.






